Contents12
- First, define the real price
- Where the naive version broke
- The core decision: split points by certainty into three layers
- Floor each layer before summing
- Separate the ranking key from the displayed price
- Leave shipping out of the real price, on purpose
- Looking back
- FAQ
- Why not just subtract all the points and compare that number?
- How do you handle limited-time points and entry-required campaigns?
- If shipping isn’t in the price, won’t the cheapest option flip?
- Why use different layers for ranking versus the displayed price?
I built and shipped a price watcher on my own. It compares the real price — sticker price minus the reward points you earn — across marketplaces, and pings you when a watched staple gets cheaper. Going in, I figured “display price minus points” was a one-liner. The moment I started writing it, that one line turned out to be the hardest part.
Three reasons. Subtract every point and you inflate the number. Mix points you’ll definitely get with points you might get, and the listing that looks cheapest turns out to be conditional. Reward rates use different units per marketplace, and get the rounding wrong and you land a few yen off the real grant.
So here are the design decisions I landed on for that real price. In short: split points into three certainty layers, floor each layer before summing, and rank on the certain layer only. If you’re computing “which is cheaper once points are in” yourself, maybe these help.
First, define the real price
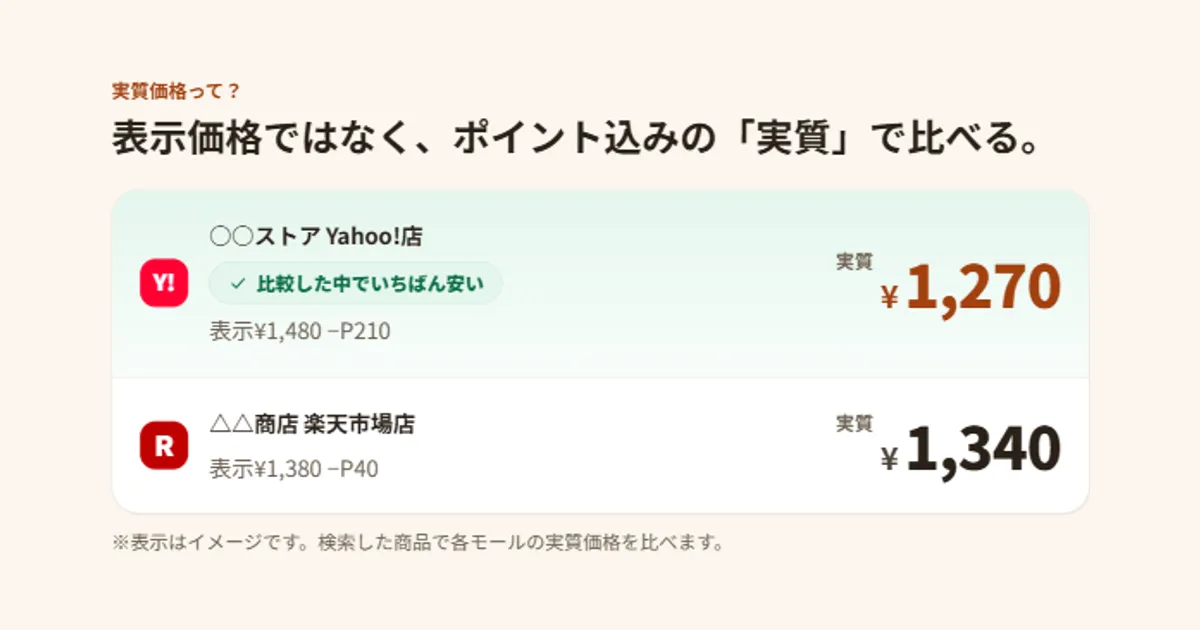
A real price is the sticker price minus the points that purchase earns you. A ¥1,000 item that returns 100 points is ¥900 real. It’s closer to what actually leaves your wallet than the sticker number is.
Points aren’t quite cash, though — they expire and they’re restricted in where you can spend them. So I fixed an assumption up front: one point equals one yen on your next purchase. Without that assumption nailed down, a cross-store comparison doesn’t even hold together. Folding the assumption into the definition was where the design started.
Where the naive version broke
The first thing I wrote was this:
const effectivePrice = displayPrice - totalPoints; // this inflatesShort, and it had three holes.
- It subtracts points you might not get. Fold in entry-required campaigns or your assumed loyalty multiplier, and the cheapest-looking store becomes “the price you reach only if every condition is met.”
- Reward rates use different units per marketplace. Rakuten’s multiplier, Yahoo’s campaign add-ons, limited-time points. Multiply them in one pass and the magnitude drifts.
- Rounding. Points usually accrue floored. Sum several rewards and then floor, and you land a few yen off the real grant.
A few yen is enough to swap first and second place — which changes the answer to “where should I buy.” Don’t inflate, and don’t drift. A real price has to do both, or it decays into a rough hint. So I rebuilt it.
The core decision: split points by certainty into three layers
The axis I settled on was splitting points by how certain you are to receive them into three layers.
| Layer | Contents | Certainty | Used for ranking |
|---|---|---|---|
| ① Confirmed | Actual points the API returns | Certain | Yes |
| ② Conditional | Known campaigns (e.g. “5 and 0 days”) | Varies (entry, etc.) | No |
| ③ Assumed | Your own loyalty multiplier / shop-hopping | Self-reported | No |
Rank on the confirmed layer alone, and show ② and ③ as “the most it could drop.” The sort order is the same for everyone — decided by certain information — while the upside flexes with each person’s conditions.
flowchart TD
Price[Sticker price incl. tax]
L1[① Confirmed: API points]
L2[② Conditional: known campaigns]
L3[③ Assumed: user settings]
Rank[Ranking rankKey = price − ①]
Eff[Displayed real price = price − ①②③]
Price --> L1 --> Rank
Price --> L2 --> Eff
Price --> L3 --> Eff
L1 --> EffEach result carries the weakest layer it includes as a certainty tier. In types, that’s all it is:
type CertaintyTier = 'confirmed' | 'conditional' | 'assumed';A rule hangs off that: a price that includes layer ③ (assumed) never fires a notification. You can’t tell someone “buy now” on the strength of self-reported points. Notifications fire on confirmed only — or on conditional once the entry requirement is disclosed.
Floor each layer before summing
Don’t floor once at the end across layers. Floor inside each layer, then add.
let pts = Math.floor(base * rate); // floor per layer
if (cap != null && pts > cap) {
pts = Math.min(pts, cap); // cap applies to floored point-yen
}Real grants are usually floored per campaign too, so summing and flooring afterward lands a yen or two off. The cap behaves the same way: take Math.min against the floored point-yen. Cap first, floor second, and you’re off by one again. Unglamorous ordering, but this is what the displayed number’s credibility rested on.
There’s a quirk in how rates are stored, too. A campaign’s “+4×” is held as the added grant on top of the tax-inclusive price — an increment. The base 1× is increment zero. Multiply the price by the raw multiplier and you double-count the standard points everyone already gets. So I store only the increment as a rate.
Separate the ranking key from the displayed price
The key that sorts and the real price I show subtract different layers.
const rankKey = base - confirmedPoints; // ① only
const total = confirmedPoints + conditionalPoints + assumedPoints;
const effectivePrice = Math.max(0, base - total); // negative guardrankKey subtracts the confirmed layer only, so the order is identical for everyone. effectivePrice subtracts every layer and represents “the most this could drop” with your conditions folded in. On high-reward items the total points can exceed the price and go negative, so Math.max(0, …) guards it.
I pulled the order apart from the displayed amount on purpose: numbers that vary by reader (conditional, assumed) shouldn’t move the ranking. Let them in and you get the queasy behavior where whoever inflated their loyalty settings most reshuffles the top.
Leave shipping out of the real price, on purpose
No marketplace search API returns the shipping amount, so I decided to keep it out of the real price. Add a guess and you import error to paper over data you don’t have.
Instead, carry a flag — shipping-included, shipping-separate, or unknown — and compare only shipping-included listings on the same footing.
// only shipping-included listings enter the main ranking
function isComparableForRank(listing: Listing): boolean {
return listing.postageFlag === 0; // 0=included, 1=separate, null=unknown
}Mix separate-shipping and included-shipping listings into one “cheapest” and you’ll miss the ones that flip once shipping lands. Deciding not to include data you can’t get — and surfacing that decision — is more honest than half-guessing it.
Looking back
A real price reads as “sticker minus points” in one line, yet making it trustworthy stacked up quiet decisions: split by certainty, floor per layer, separate the ranking key, drop shipping. None of it is flashy. Do it sloppily, though, and “the cheapest one was actually conditional” costs you the reader’s trust. Most of the time I spent went into making this calculation’s footing solid.
This three-layer calculation runs on watched staples every day, pinging only when the confirmed layer says something genuinely got cheaper. The watcher I built around it — now live — is yasugoro: free, no login required.
FAQ
Why not just subtract all the points and compare that number?
Subtracting everything inflates the number. A price with entry-required campaigns and your own loyalty multiplier baked in is “the price you reach if every condition is met” — not a floor everyone can count on. Rank on the points the API actually confirms, and show conditional and assumed points as a separate range.
How do you handle limited-time points and entry-required campaigns?
They don’t go into the effective-price total. They live in a conditional layer, computed separately and flagged for “entry required” or “cap reached”. Only API-confirmed points are asserted as a firm amount. Conditional points are shown as “this is the most it could drop”, and they’re excluded from what triggers a notification.
If shipping isn’t in the price, won’t the cheapest option flip?
It can. But no marketplace search API returns the shipping amount, so adding a guess just imports error. I kept shipping out of the effective price and instead carry a flag — shipping-included, shipping-separate, or unknown — comparing only shipping-included listings on the same footing. Separate-shipping listings drop out of the main ranking and are disclosed in a note.
Why use different layers for ranking versus the displayed price?
The sort order should look the same to everyone. The ranking key uses only the confirmed layer, while the displayed effective price subtracts confirmed plus conditional plus assumed. That way “cheapest first” is decided by certain information alone, and the per-person upside shows up as a range on the displayed price.